Now that we have some experience with CNNs let us try some transfer learning. Transfer learning is a method of reusing a model or knowledge for another related task. Transfer learning can be considered as spanning four scenarios:
In this excercise we follow the examples laid out by Dipanjan Sarkar, Raghav Bali and Tamoghna Ghosh in thier book ‘Transfer Learning with Python’ begining with an example of classification on the kaggle Dogs vs Cats data set.
import glob
import numpy as np
import matplotlib.pyplot as plt
from keras.preprocessing.image import ImageDataGenerator, load_img, img_to_array, array_to_img
%matplotlib inline
from keras import backend as K
K.tensorflow_backend._get_available_gpus()
['/job:localhost/replica:0/task:0/device:GPU:0']
from heardingcats import heard
heard()
Cat datasets: (1500,) (500,) (500,)
Dog datasets: (1500,) (500,) (500,)
IMG_DIM = (150, 150)
train_files = glob.glob('training_data/*')
train_imgs = [img_to_array(load_img(img, target_size=IMG_DIM)) for img in train_files]
train_imgs = np.array(train_imgs, dtype='float32')
train_labels = [fn.split('/')[1].split('.')[0].strip() for fn in train_files]
validation_files = glob.glob('validation_data/*')
validation_imgs = [img_to_array(load_img(img, target_size=IMG_DIM)) for img in validation_files]
validation_imgs = np.array(validation_imgs, dtype='float32')
validation_labels = [fn.split('/')[1].split('.')[0].strip() for fn in validation_files]
print('Train dataset shape:', train_imgs.shape,
'\tValidation dataset shape:', validation_imgs.shape)
Train dataset shape: (3000, 150, 150, 3) Validation dataset shape: (2850, 150, 150, 3)
print("overall",train_imgs.shape)
print(train_imgs[0].shape)
array_to_img(train_imgs[0])
overall (3000, 150, 150, 3)
(150, 150, 3)

We scale each image with pixel values between (0, 255) to values between (0, 1) in order to improve performance:
train_imgs_scaled = train_imgs / 255.
validation_imgs_scaled = validation_imgs / 255
first we set up some basic configuration parameters and also encode our text class labels into numeric values (otherwise, Keras will throw an error):
batch_size = 30
num_classes = 2
epochs = 30
input_shape = (150, 150, 3)
# encode text category labels
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
le.fit(train_labels)
train_labels_enc = le.transform(train_labels)
validation_labels_enc = le.transform(validation_labels)
print(train_labels[1495:1505], train_labels_enc[1495:1505])
['dog', 'dog', 'cat', 'cat', 'cat', 'dog', 'cat', 'cat', 'dog', 'cat'] [1 1 0 0 0 1 0 0 1 0]
This basic CNN model has three convolutional layers, coupled with max pooling for auto-extraction of features from the images and also downsampling the output convolution feature maps.
After extracting some feature maps, one dense layer is used along with an output layer with a sigmoid function for classification. Since we are doing binary classification, a binary_crossentropy loss function will suffice. The RMSprop optimizer is used.
from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
from keras.models import Sequential
from keras import optimizers
model = Sequential()
model.add(Conv2D(16, kernel_size=(3, 3), activation='relu',
input_shape=input_shape))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(512, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(),
metrics=['accuracy'])
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 148, 148, 16) 448
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 74, 74, 16) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 72, 72, 64) 9280
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 36, 36, 64) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 34, 34, 128) 73856
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 17, 17, 128) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 36992) 0
_________________________________________________________________
dense_1 (Dense) (None, 512) 18940416
_________________________________________________________________
dense_2 (Dense) (None, 1) 513
=================================================================
Total params: 19,024,513
Trainable params: 19,024,513
Non-trainable params: 0
_________________________________________________________________
The flatten layer is used to flatten out 128 of the 17 x 17 feature maps that we get as output from the third convolution layer. This is fed to our dense layers to get the final prediction of whether the image should be a dog (1) or a cat (0). All of this is part of the model training process, so let’s train our model using the following snippet which leverages the fit(…) function. The following terminology is very important with regard to training our model:
history = model.fit(x=train_imgs_scaled, y=train_labels_enc,
validation_data=(validation_imgs_scaled, validation_labels_enc),
batch_size=batch_size,
epochs=epochs,
verbose=1)
Train on 3000 samples, validate on 2850 samples
Epoch 1/30
3000/3000 [==============================] - 11s 4ms/step - loss: 0.8663 - acc: 0.5790 - val_loss: 0.6648 - val_acc: 0.6123
Epoch 2/30
3000/3000 [==============================] - 10s 3ms/step - loss: 0.6289 - acc: 0.6633 - val_loss: 0.6085 - val_acc: 0.6818
Epoch 3/30
3000/3000 [==============================] - 10s 3ms/step - loss: 0.5499 - acc: 0.7227 - val_loss: 0.9491 - val_acc: 0.5632
Epoch 4/30
3000/3000 [==============================] - 10s 3ms/step - loss: 0.4920 - acc: 0.7703 - val_loss: 0.6632 - val_acc: 0.6933
Epoch 5/30
3000/3000 [==============================] - 10s 3ms/step - loss: 0.4160 - acc: 0.8080 - val_loss: 0.5847 - val_acc: 0.7225
Epoch 6/30
3000/3000 [==============================] - 10s 3ms/step - loss: 0.3345 - acc: 0.8493 - val_loss: 0.6202 - val_acc: 0.7207
Epoch 7/30
3000/3000 [==============================] - 10s 3ms/step - loss: 0.2463 - acc: 0.8890 - val_loss: 0.7032 - val_acc: 0.7246
Epoch 8/30
3000/3000 [==============================] - 10s 3ms/step - loss: 0.1761 - acc: 0.9337 - val_loss: 0.8775 - val_acc: 0.7112
Epoch 9/30
3000/3000 [==============================] - 10s 3ms/step - loss: 0.1131 - acc: 0.9560 - val_loss: 0.8502 - val_acc: 0.7186
Epoch 10/30
3000/3000 [==============================] - 10s 3ms/step - loss: 0.0704 - acc: 0.9760 - val_loss: 1.2393 - val_acc: 0.7088
Epoch 11/30
3000/3000 [==============================] - 10s 3ms/step - loss: 0.0741 - acc: 0.9760 - val_loss: 1.5347 - val_acc: 0.7179
Epoch 12/30
3000/3000 [==============================] - 10s 3ms/step - loss: 0.0545 - acc: 0.9837 - val_loss: 1.5646 - val_acc: 0.7126
Epoch 13/30
3000/3000 [==============================] - 10s 3ms/step - loss: 0.0251 - acc: 0.9927 - val_loss: 1.8411 - val_acc: 0.7109
Epoch 14/30
3000/3000 [==============================] - 10s 3ms/step - loss: 0.0466 - acc: 0.9883 - val_loss: 1.7311 - val_acc: 0.7200
Epoch 15/30
3000/3000 [==============================] - 10s 3ms/step - loss: 0.0224 - acc: 0.9933 - val_loss: 1.7674 - val_acc: 0.7232
Epoch 16/30
3000/3000 [==============================] - 10s 3ms/step - loss: 0.0238 - acc: 0.9910 - val_loss: 1.9221 - val_acc: 0.6951
Epoch 17/30
3000/3000 [==============================] - 10s 3ms/step - loss: 0.0307 - acc: 0.9943 - val_loss: 2.2236 - val_acc: 0.7049
Epoch 18/30
3000/3000 [==============================] - 10s 3ms/step - loss: 0.0452 - acc: 0.9913 - val_loss: 1.9217 - val_acc: 0.7189
Epoch 19/30
3000/3000 [==============================] - 10s 3ms/step - loss: 0.0695 - acc: 0.9870 - val_loss: 1.8419 - val_acc: 0.7046
Epoch 20/30
3000/3000 [==============================] - 10s 3ms/step - loss: 0.0220 - acc: 0.9947 - val_loss: 2.1624 - val_acc: 0.7130
Epoch 21/30
3000/3000 [==============================] - 10s 3ms/step - loss: 0.0262 - acc: 0.9933 - val_loss: 1.8506 - val_acc: 0.6940
Epoch 22/30
3000/3000 [==============================] - 10s 3ms/step - loss: 0.0536 - acc: 0.9927 - val_loss: 2.0859 - val_acc: 0.7196
Epoch 23/30
3000/3000 [==============================] - 10s 3ms/step - loss: 0.0704 - acc: 0.9903 - val_loss: 2.3948 - val_acc: 0.7007
Epoch 24/30
3000/3000 [==============================] - 10s 3ms/step - loss: 0.0177 - acc: 0.9953 - val_loss: 2.2990 - val_acc: 0.7116
Epoch 25/30
3000/3000 [==============================] - 10s 3ms/step - loss: 0.0503 - acc: 0.9910 - val_loss: 2.0304 - val_acc: 0.7091
Epoch 26/30
3000/3000 [==============================] - 10s 3ms/step - loss: 0.0471 - acc: 0.9923 - val_loss: 2.3504 - val_acc: 0.7200
Epoch 27/30
3000/3000 [==============================] - 10s 3ms/step - loss: 0.0312 - acc: 0.9930 - val_loss: 2.3321 - val_acc: 0.7158
Epoch 28/30
3000/3000 [==============================] - 10s 3ms/step - loss: 0.0281 - acc: 0.9957 - val_loss: 2.3050 - val_acc: 0.7077
Epoch 29/30
3000/3000 [==============================] - 10s 3ms/step - loss: 0.0491 - acc: 0.9900 - val_loss: 1.8814 - val_acc: 0.7028
Epoch 30/30
3000/3000 [==============================] - 10s 3ms/step - loss: 0.0379 - acc: 0.9910 - val_loss: 2.2621 - val_acc: 0.7133
f, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 4))
t = f.suptitle('Regularised CNN Performance', fontsize=12)
f.subplots_adjust(top=0.85, wspace=0.3)
epoch_list = list(range(1,epochs+1))
ax1.plot(epoch_list, history.history['acc'], label='Train Accuracy')
ax1.plot(epoch_list, history.history['val_acc'], label='Validation Accuracy')
ax1.set_xticks(np.arange(0, 10, 5))
ax1.set_ylabel('Accuracy Value')
ax1.set_xlabel('Epoch')
ax1.set_title('Accuracy')
l1 = ax1.legend(loc="best")
ax2.plot(epoch_list, history.history['loss'], label='Train Loss')
ax2.plot(epoch_list, history.history['val_loss'], label='Validation Loss')
ax2.set_xticks(np.arange(0, 10, 5))
ax2.set_ylabel('Loss Value')
ax2.set_xlabel('Epoch')
ax2.set_title('Loss')
l2 = ax2.legend(loc="best")
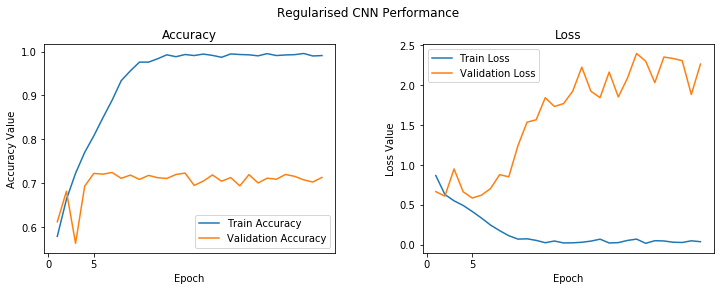
Plotting the model accuracy and errors as above can give a better perspective on whether or not the model is over fitting.
Our first attempt to add some knowledge of the model will be throught the use of regularisation. It could be that majority of training images have white dogs and black cats and therefore the model is giving too much preference to this one feature. Regularisation adds some knowledge of the problem, in that it forces the model to give higher creedence to more subtle features.
To do this we improve our base CNN model by adding in one more convolution layer, another dense hidden layer. Besides this, we will add dropout of 0.3 after each hidden dense layer to enable regularization.
Dropout randomly masks the outputs of a fraction of units from a layer by setting their output to zero (in our case, it is 30% of the units in our dense layers):
model = Sequential()
# convolutional and pooling layers
model.add(Conv2D(16, kernel_size=(3, 3), activation='relu',
input_shape=input_shape))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.3))
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.3))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(),
metrics=['accuracy'])
history = model.fit(x=train_imgs_scaled, y=train_labels_enc,
validation_data=(validation_imgs_scaled,
validation_labels_enc),
batch_size=batch_size,
epochs=epochs,
verbose=1)
Train on 3000 samples, validate on 2850 samples
Epoch 1/30
3000/3000 [==============================] - 9s 3ms/step - loss: 0.7134 - acc: 0.5400 - val_loss: 0.6666 - val_acc: 0.5772
Epoch 2/30
3000/3000 [==============================] - 9s 3ms/step - loss: 0.6543 - acc: 0.6197 - val_loss: 0.6113 - val_acc: 0.6582
Epoch 3/30
3000/3000 [==============================] - 9s 3ms/step - loss: 0.6194 - acc: 0.6660 - val_loss: 0.6216 - val_acc: 0.6333
Epoch 4/30
3000/3000 [==============================] - 9s 3ms/step - loss: 0.5777 - acc: 0.7003 - val_loss: 0.5869 - val_acc: 0.6968
Epoch 5/30
3000/3000 [==============================] - 9s 3ms/step - loss: 0.5429 - acc: 0.7303 - val_loss: 0.7922 - val_acc: 0.6768
Epoch 6/30
3000/3000 [==============================] - 9s 3ms/step - loss: 0.4977 - acc: 0.7563 - val_loss: 0.5748 - val_acc: 0.6933
Epoch 7/30
3000/3000 [==============================] - 9s 3ms/step - loss: 0.4492 - acc: 0.7907 - val_loss: 0.5592 - val_acc: 0.7382
Epoch 8/30
3000/3000 [==============================] - 9s 3ms/step - loss: 0.4043 - acc: 0.8100 - val_loss: 0.5814 - val_acc: 0.7421
Epoch 9/30
3000/3000 [==============================] - 9s 3ms/step - loss: 0.3640 - acc: 0.8380 - val_loss: 0.5489 - val_acc: 0.7572
Epoch 10/30
3000/3000 [==============================] - 9s 3ms/step - loss: 0.3236 - acc: 0.8637 - val_loss: 0.5484 - val_acc: 0.7411
Epoch 11/30
3000/3000 [==============================] - 9s 3ms/step - loss: 0.2676 - acc: 0.8873 - val_loss: 0.6509 - val_acc: 0.7530
Epoch 12/30
3000/3000 [==============================] - 9s 3ms/step - loss: 0.2294 - acc: 0.9030 - val_loss: 0.6938 - val_acc: 0.7519
Epoch 13/30
3000/3000 [==============================] - 9s 3ms/step - loss: 0.1847 - acc: 0.9237 - val_loss: 0.8692 - val_acc: 0.7621
Epoch 14/30
3000/3000 [==============================] - 9s 3ms/step - loss: 0.1702 - acc: 0.9383 - val_loss: 1.0422 - val_acc: 0.7593
Epoch 15/30
3000/3000 [==============================] - 9s 3ms/step - loss: 0.1662 - acc: 0.9450 - val_loss: 1.0333 - val_acc: 0.7498
Epoch 16/30
3000/3000 [==============================] - 9s 3ms/step - loss: 0.1304 - acc: 0.9520 - val_loss: 1.0184 - val_acc: 0.7639
Epoch 17/30
3000/3000 [==============================] - 9s 3ms/step - loss: 0.1321 - acc: 0.9510 - val_loss: 1.2059 - val_acc: 0.7284
Epoch 18/30
3000/3000 [==============================] - 9s 3ms/step - loss: 0.1094 - acc: 0.9630 - val_loss: 1.3118 - val_acc: 0.7582
Epoch 19/30
3000/3000 [==============================] - 9s 3ms/step - loss: 0.1114 - acc: 0.9633 - val_loss: 1.1543 - val_acc: 0.7453
Epoch 20/30
3000/3000 [==============================] - 9s 3ms/step - loss: 0.0831 - acc: 0.9747 - val_loss: 1.5643 - val_acc: 0.7533
Epoch 21/30
3000/3000 [==============================] - 9s 3ms/step - loss: 0.0977 - acc: 0.9700 - val_loss: 1.9108 - val_acc: 0.7182
Epoch 22/30
3000/3000 [==============================] - 9s 3ms/step - loss: 0.0884 - acc: 0.9707 - val_loss: 1.5787 - val_acc: 0.7081
Epoch 23/30
3000/3000 [==============================] - 9s 3ms/step - loss: 0.0895 - acc: 0.9803 - val_loss: 1.6132 - val_acc: 0.7674
Epoch 24/30
3000/3000 [==============================] - 9s 3ms/step - loss: 0.0959 - acc: 0.9753 - val_loss: 1.5740 - val_acc: 0.7498
Epoch 25/30
3000/3000 [==============================] - 9s 3ms/step - loss: 0.0822 - acc: 0.9743 - val_loss: 1.4073 - val_acc: 0.7323
Epoch 26/30
3000/3000 [==============================] - 9s 3ms/step - loss: 0.0749 - acc: 0.9753 - val_loss: 1.7459 - val_acc: 0.7396
Epoch 27/30
3000/3000 [==============================] - 9s 3ms/step - loss: 0.0724 - acc: 0.9807 - val_loss: 1.6105 - val_acc: 0.7572
Epoch 28/30
3000/3000 [==============================] - 9s 3ms/step - loss: 0.0697 - acc: 0.9800 - val_loss: 1.3913 - val_acc: 0.7411
Epoch 29/30
3000/3000 [==============================] - 9s 3ms/step - loss: 0.0834 - acc: 0.9777 - val_loss: 1.8184 - val_acc: 0.7407
Epoch 30/30
3000/3000 [==============================] - 9s 3ms/step - loss: 0.0789 - acc: 0.9800 - val_loss: 1.6869 - val_acc: 0.7582
f, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 4))
t = f.suptitle('Regularised CNN Performance', fontsize=12)
f.subplots_adjust(top=0.85, wspace=0.3)
epoch_list = list(range(1,31))
ax1.plot(epoch_list, history.history['acc'], label='Train Accuracy')
ax1.plot(epoch_list, history.history['val_acc'], label='Validation Accuracy')
ax1.set_xticks(np.arange(0, 31, 5))
ax1.set_ylabel('Accuracy Value')
ax1.set_xlabel('Epoch')
ax1.set_title('Accuracy')
l1 = ax1.legend(loc="best")
ax2.plot(epoch_list, history.history['loss'], label='Train Loss')
ax2.plot(epoch_list, history.history['val_loss'], label='Validation Loss')
ax2.set_xticks(np.arange(0, 31, 5))
ax2.set_ylabel('Loss Value')
ax2.set_xlabel('Epoch')
ax2.set_title('Loss')
l2 = ax2.legend(loc="best")
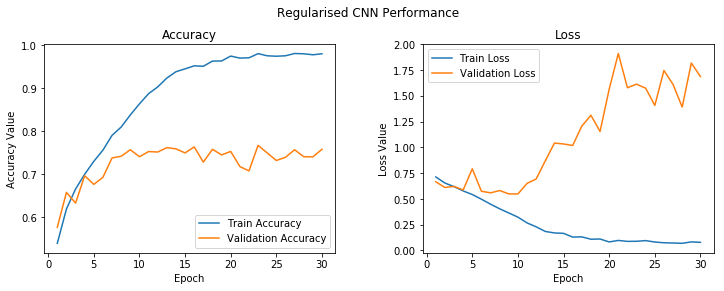
You can clearly see from the preceding outputs that we still end up overfitting the model, though it takes slightly longer and we also get a slightly better validation accuracy of around 78%, which is decent but not amazing.
model.save('cats_dogs_regularised_cnn.h5')
Here we leverage an image augmentation strategy to augment our existing training data with images that are slight variations of the existing images.
The idea behind image augmentation is that we follow a set process of taking in existing images from our training dataset and applying some image transformation operations to them, such as rotation, shearing, translation, zooming, and so on, to produce new, altered versions of existing images. Due to these random transformations, we don’t get the same images each time, and we will leverage Python generators to feed in these new images to our model during training.
The Keras framework has an excellent utility called ImageDataGenerator that can help us in doing all the preceding operations. Let’s initialize two of the data generators for our training and validation datasets:
train_datagen = ImageDataGenerator(rescale=1./255, zoom_range=0.3,
rotation_range=50,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
val_datagen = ImageDataGenerator(rescale=1./255)
Let’s see how some of these generated images might look so that you can understand them better. We will take two sample images from our training dataset to illustrate the same. The first image is an image of a cat:
img_id = 2595
cat_generator = train_datagen.flow(train_imgs[img_id:img_id+1],
train_labels[img_id:img_id+1],
batch_size=1)
cat = [next(cat_generator) for i in range(0,5)]
fig, ax = plt.subplots(1,5, figsize=(16, 6))
print('Labels:', [item[1][0] for item in cat])
l = [ax[i].imshow(cat[i][0][0]) for i in range(0,5)]
Labels: ['cat', 'cat', 'cat', 'cat', 'cat']

train_generator = train_datagen.flow(train_imgs, train_labels_enc,
batch_size=30)
val_generator = val_datagen.flow(validation_imgs,
validation_labels_enc,
batch_size=20)
input_shape = (150, 150, 3)
Now lets define our new model.
model = Sequential()
# convolution and pooling layers
model.add(Conv2D(16, kernel_size=(3, 3), activation='relu',
input_shape=input_shape))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.3))
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.3))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['accuracy'])
We reduce the default learning rate by a factor of 10 here for our optimizer to prevent the model from getting stuck in a local minima or overfit, as we will be sending a lot of images with random transformations. To train the model, we need to slightly modify our approach now, since we are using data generators. We will leverage the fit_generator(…) function from Keras to train this model. The train_generator generates 30 images each time, so we will use the steps_per_epoch parameter and set it to 100 to train the model on 3,000 randomly generated images from the training data for each epoch. Our val_generator generates 20 images each time so we will set the validation_steps parameter to 50 to validate our model accuracy on all the 1,000 validation images (remember we are not augmenting our validation dataset):
history = model.fit_generator(train_generator,
steps_per_epoch=100, epochs=100,
validation_data=val_generator,
validation_steps=50, verbose=1)
Epoch 1/100
100/100 [==============================] - 16s 163ms/step - loss: 0.6923 - acc: 0.5253 - val_loss: 0.6861 - val_acc: 0.5050
Epoch 2/100
100/100 [==============================] - 16s 158ms/step - loss: 0.6795 - acc: 0.5630 - val_loss: 0.7065 - val_acc: 0.5090
Epoch 3/100
100/100 [==============================] - 16s 159ms/step - loss: 0.6703 - acc: 0.5893 - val_loss: 0.6773 - val_acc: 0.5700
Epoch 4/100
100/100 [==============================] - 16s 162ms/step - loss: 0.6574 - acc: 0.6187 - val_loss: 0.6775 - val_acc: 0.5660
Epoch 5/100
100/100 [==============================] - 16s 157ms/step - loss: 0.6514 - acc: 0.6093 - val_loss: 0.6357 - val_acc: 0.6390
Epoch 6/100
100/100 [==============================] - 16s 157ms/step - loss: 0.6355 - acc: 0.6390 - val_loss: 0.6211 - val_acc: 0.6470
Epoch 7/100
100/100 [==============================] - 16s 160ms/step - loss: 0.6253 - acc: 0.6550 - val_loss: 0.6045 - val_acc: 0.6640
Epoch 8/100
100/100 [==============================] - 16s 157ms/step - loss: 0.5997 - acc: 0.6783 - val_loss: 0.5722 - val_acc: 0.6890
Epoch 9/100
100/100 [==============================] - 16s 158ms/step - loss: 0.5960 - acc: 0.6810 - val_loss: 0.5659 - val_acc: 0.6970
Epoch 10/100
100/100 [==============================] - 15s 155ms/step - loss: 0.5927 - acc: 0.6720 - val_loss: 0.6055 - val_acc: 0.6700
Epoch 11/100
100/100 [==============================] - 16s 158ms/step - loss: 0.5857 - acc: 0.6860 - val_loss: 0.5563 - val_acc: 0.7180
Epoch 12/100
100/100 [==============================] - 16s 159ms/step - loss: 0.5810 - acc: 0.6937 - val_loss: 0.6767 - val_acc: 0.6630
Epoch 13/100
100/100 [==============================] - 16s 159ms/step - loss: 0.5785 - acc: 0.6913 - val_loss: 0.5569 - val_acc: 0.7150
Epoch 14/100
100/100 [==============================] - 16s 158ms/step - loss: 0.5768 - acc: 0.6933 - val_loss: 0.5483 - val_acc: 0.7150
Epoch 15/100
100/100 [==============================] - 16s 157ms/step - loss: 0.5722 - acc: 0.6960 - val_loss: 0.5838 - val_acc: 0.6860
Epoch 16/100
100/100 [==============================] - 16s 159ms/step - loss: 0.5672 - acc: 0.6997 - val_loss: 0.5496 - val_acc: 0.7130
Epoch 17/100
100/100 [==============================] - 16s 159ms/step - loss: 0.5643 - acc: 0.7133 - val_loss: 0.5615 - val_acc: 0.7280
Epoch 18/100
100/100 [==============================] - 16s 161ms/step - loss: 0.5497 - acc: 0.7180 - val_loss: 0.5532 - val_acc: 0.7270
Epoch 19/100
100/100 [==============================] - 16s 162ms/step - loss: 0.5408 - acc: 0.7173 - val_loss: 0.5865 - val_acc: 0.7070
Epoch 20/100
100/100 [==============================] - 16s 159ms/step - loss: 0.5503 - acc: 0.7100 - val_loss: 0.5484 - val_acc: 0.7250
Epoch 21/100
100/100 [==============================] - 16s 159ms/step - loss: 0.5339 - acc: 0.7273 - val_loss: 0.6189 - val_acc: 0.6880
Epoch 22/100
100/100 [==============================] - 16s 160ms/step - loss: 0.5311 - acc: 0.7257 - val_loss: 0.5467 - val_acc: 0.7140
Epoch 23/100
100/100 [==============================] - 16s 159ms/step - loss: 0.5437 - acc: 0.7220 - val_loss: 0.5367 - val_acc: 0.7290
Epoch 24/100
100/100 [==============================] - 16s 158ms/step - loss: 0.5241 - acc: 0.7393 - val_loss: 0.5363 - val_acc: 0.7440
Epoch 25/100
100/100 [==============================] - 16s 161ms/step - loss: 0.5243 - acc: 0.7333 - val_loss: 0.5322 - val_acc: 0.7390
Epoch 26/100
100/100 [==============================] - 16s 160ms/step - loss: 0.5188 - acc: 0.7390 - val_loss: 0.5101 - val_acc: 0.7460
Epoch 27/100
100/100 [==============================] - 16s 159ms/step - loss: 0.5164 - acc: 0.7393 - val_loss: 0.5143 - val_acc: 0.7430
Epoch 28/100
100/100 [==============================] - 15s 154ms/step - loss: 0.5215 - acc: 0.7320 - val_loss: 0.5228 - val_acc: 0.7460
Epoch 29/100
100/100 [==============================] - 16s 157ms/step - loss: 0.5094 - acc: 0.7433 - val_loss: 0.4979 - val_acc: 0.7610
Epoch 30/100
100/100 [==============================] - 16s 160ms/step - loss: 0.5077 - acc: 0.7463 - val_loss: 0.5067 - val_acc: 0.7570
Epoch 31/100
100/100 [==============================] - 16s 159ms/step - loss: 0.4971 - acc: 0.7497 - val_loss: 0.5164 - val_acc: 0.7560
Epoch 32/100
100/100 [==============================] - 16s 158ms/step - loss: 0.5105 - acc: 0.7463 - val_loss: 0.4794 - val_acc: 0.7740
Epoch 33/100
100/100 [==============================] - 16s 159ms/step - loss: 0.4911 - acc: 0.7633 - val_loss: 0.4913 - val_acc: 0.7740
Epoch 34/100
100/100 [==============================] - 16s 160ms/step - loss: 0.5037 - acc: 0.7517 - val_loss: 0.5156 - val_acc: 0.7460
Epoch 35/100
100/100 [==============================] - 16s 158ms/step - loss: 0.4884 - acc: 0.7613 - val_loss: 0.5206 - val_acc: 0.7610
Epoch 36/100
100/100 [==============================] - 16s 157ms/step - loss: 0.4924 - acc: 0.7617 - val_loss: 0.5178 - val_acc: 0.7630
Epoch 37/100
100/100 [==============================] - 16s 159ms/step - loss: 0.4897 - acc: 0.7633 - val_loss: 0.5162 - val_acc: 0.7570
Epoch 38/100
100/100 [==============================] - 16s 158ms/step - loss: 0.4875 - acc: 0.7643 - val_loss: 0.5645 - val_acc: 0.7350
Epoch 39/100
100/100 [==============================] - 16s 162ms/step - loss: 0.4949 - acc: 0.7560 - val_loss: 0.5508 - val_acc: 0.7360
Epoch 40/100
100/100 [==============================] - 16s 156ms/step - loss: 0.4895 - acc: 0.7673 - val_loss: 0.5107 - val_acc: 0.7590
Epoch 41/100
100/100 [==============================] - 16s 158ms/step - loss: 0.4851 - acc: 0.7633 - val_loss: 0.4877 - val_acc: 0.7830
Epoch 42/100
100/100 [==============================] - 16s 158ms/step - loss: 0.4711 - acc: 0.7757 - val_loss: 0.5400 - val_acc: 0.7440
Epoch 43/100
100/100 [==============================] - 16s 161ms/step - loss: 0.4695 - acc: 0.7740 - val_loss: 0.4706 - val_acc: 0.7850
Epoch 44/100
100/100 [==============================] - 16s 157ms/step - loss: 0.4750 - acc: 0.7770 - val_loss: 0.4834 - val_acc: 0.7720
Epoch 45/100
100/100 [==============================] - 16s 160ms/step - loss: 0.4698 - acc: 0.7800 - val_loss: 0.5799 - val_acc: 0.7320
Epoch 46/100
100/100 [==============================] - 16s 158ms/step - loss: 0.4759 - acc: 0.7707 - val_loss: 0.4804 - val_acc: 0.7740
Epoch 47/100
100/100 [==============================] - 16s 157ms/step - loss: 0.4670 - acc: 0.7820 - val_loss: 0.4414 - val_acc: 0.7960
Epoch 48/100
100/100 [==============================] - 16s 158ms/step - loss: 0.4708 - acc: 0.7830 - val_loss: 0.4506 - val_acc: 0.8000
Epoch 49/100
100/100 [==============================] - 16s 161ms/step - loss: 0.4672 - acc: 0.7747 - val_loss: 0.4504 - val_acc: 0.7930
Epoch 50/100
100/100 [==============================] - 16s 157ms/step - loss: 0.4607 - acc: 0.7870 - val_loss: 0.4596 - val_acc: 0.7910
Epoch 51/100
100/100 [==============================] - 16s 157ms/step - loss: 0.4580 - acc: 0.7803 - val_loss: 0.5267 - val_acc: 0.7680
Epoch 52/100
100/100 [==============================] - 16s 161ms/step - loss: 0.4593 - acc: 0.7807 - val_loss: 0.4594 - val_acc: 0.7950
Epoch 53/100
100/100 [==============================] - 16s 159ms/step - loss: 0.4471 - acc: 0.7857 - val_loss: 0.4769 - val_acc: 0.7790
Epoch 54/100
100/100 [==============================] - 16s 157ms/step - loss: 0.4555 - acc: 0.7883 - val_loss: 0.4435 - val_acc: 0.7990
Epoch 55/100
100/100 [==============================] - 16s 158ms/step - loss: 0.4487 - acc: 0.7803 - val_loss: 0.4493 - val_acc: 0.8020
Epoch 56/100
100/100 [==============================] - 16s 159ms/step - loss: 0.4426 - acc: 0.7843 - val_loss: 0.5240 - val_acc: 0.7750
Epoch 57/100
100/100 [==============================] - 16s 159ms/step - loss: 0.4529 - acc: 0.7893 - val_loss: 0.4758 - val_acc: 0.7750
Epoch 58/100
100/100 [==============================] - 16s 161ms/step - loss: 0.4445 - acc: 0.7870 - val_loss: 0.4422 - val_acc: 0.7910
Epoch 59/100
100/100 [==============================] - 16s 158ms/step - loss: 0.4319 - acc: 0.7983 - val_loss: 0.4781 - val_acc: 0.7690
Epoch 60/100
100/100 [==============================] - 15s 153ms/step - loss: 0.4303 - acc: 0.8073 - val_loss: 0.4342 - val_acc: 0.8070
Epoch 61/100
100/100 [==============================] - 16s 159ms/step - loss: 0.4278 - acc: 0.7987 - val_loss: 0.5046 - val_acc: 0.7770
Epoch 62/100
100/100 [==============================] - 16s 158ms/step - loss: 0.4382 - acc: 0.7910 - val_loss: 0.4706 - val_acc: 0.7890
Epoch 63/100
100/100 [==============================] - 16s 159ms/step - loss: 0.4358 - acc: 0.7983 - val_loss: 0.4797 - val_acc: 0.7900
Epoch 64/100
100/100 [==============================] - 16s 159ms/step - loss: 0.4414 - acc: 0.7927 - val_loss: 0.4571 - val_acc: 0.7880
Epoch 65/100
100/100 [==============================] - 16s 156ms/step - loss: 0.4248 - acc: 0.8017 - val_loss: 0.4737 - val_acc: 0.7930
Epoch 66/100
100/100 [==============================] - 16s 159ms/step - loss: 0.4322 - acc: 0.8057 - val_loss: 0.4334 - val_acc: 0.8020
Epoch 67/100
100/100 [==============================] - 16s 160ms/step - loss: 0.4231 - acc: 0.8037 - val_loss: 0.4474 - val_acc: 0.7910
Epoch 68/100
100/100 [==============================] - 16s 161ms/step - loss: 0.4260 - acc: 0.8040 - val_loss: 0.4539 - val_acc: 0.7920
Epoch 69/100
100/100 [==============================] - 16s 159ms/step - loss: 0.4321 - acc: 0.8053 - val_loss: 0.4580 - val_acc: 0.8010
Epoch 70/100
100/100 [==============================] - 16s 161ms/step - loss: 0.4128 - acc: 0.8133 - val_loss: 0.4849 - val_acc: 0.7770
Epoch 71/100
100/100 [==============================] - 16s 157ms/step - loss: 0.4194 - acc: 0.8070 - val_loss: 0.4472 - val_acc: 0.8040
Epoch 72/100
100/100 [==============================] - 16s 159ms/step - loss: 0.4272 - acc: 0.7967 - val_loss: 0.4147 - val_acc: 0.8150
Epoch 73/100
100/100 [==============================] - 16s 157ms/step - loss: 0.4105 - acc: 0.8197 - val_loss: 0.4115 - val_acc: 0.8180
Epoch 74/100
100/100 [==============================] - 16s 157ms/step - loss: 0.4205 - acc: 0.8063 - val_loss: 0.4270 - val_acc: 0.7990
Epoch 75/100
100/100 [==============================] - 16s 159ms/step - loss: 0.4074 - acc: 0.8130 - val_loss: 0.4841 - val_acc: 0.7970
Epoch 76/100
100/100 [==============================] - 16s 160ms/step - loss: 0.3947 - acc: 0.8157 - val_loss: 0.4091 - val_acc: 0.8070
Epoch 77/100
100/100 [==============================] - 16s 157ms/step - loss: 0.4030 - acc: 0.8210 - val_loss: 0.4266 - val_acc: 0.8010
Epoch 78/100
100/100 [==============================] - 16s 160ms/step - loss: 0.4101 - acc: 0.8163 - val_loss: 0.4499 - val_acc: 0.8170
Epoch 79/100
100/100 [==============================] - 16s 160ms/step - loss: 0.4071 - acc: 0.8153 - val_loss: 0.4156 - val_acc: 0.8140
Epoch 80/100
100/100 [==============================] - 16s 157ms/step - loss: 0.4009 - acc: 0.8253 - val_loss: 0.4055 - val_acc: 0.8050
Epoch 81/100
100/100 [==============================] - 16s 160ms/step - loss: 0.4039 - acc: 0.8233 - val_loss: 0.4068 - val_acc: 0.8280
Epoch 82/100
100/100 [==============================] - 16s 160ms/step - loss: 0.4010 - acc: 0.8230 - val_loss: 0.4575 - val_acc: 0.7920
Epoch 83/100
100/100 [==============================] - 16s 158ms/step - loss: 0.3938 - acc: 0.8193 - val_loss: 0.4232 - val_acc: 0.8010
Epoch 84/100
100/100 [==============================] - 16s 160ms/step - loss: 0.3951 - acc: 0.8213 - val_loss: 0.5223 - val_acc: 0.7590
Epoch 85/100
100/100 [==============================] - 16s 159ms/step - loss: 0.3967 - acc: 0.8247 - val_loss: 0.4528 - val_acc: 0.8200
Epoch 86/100
100/100 [==============================] - 16s 156ms/step - loss: 0.3870 - acc: 0.8170 - val_loss: 0.3952 - val_acc: 0.8330
Epoch 87/100
100/100 [==============================] - 16s 159ms/step - loss: 0.3898 - acc: 0.8250 - val_loss: 0.4920 - val_acc: 0.8060
Epoch 88/100
100/100 [==============================] - 16s 158ms/step - loss: 0.3856 - acc: 0.8233 - val_loss: 0.4137 - val_acc: 0.8260
Epoch 89/100
100/100 [==============================] - 16s 159ms/step - loss: 0.3866 - acc: 0.8280 - val_loss: 0.4371 - val_acc: 0.8190
Epoch 90/100
100/100 [==============================] - 16s 159ms/step - loss: 0.3855 - acc: 0.8267 - val_loss: 0.4643 - val_acc: 0.7950
Epoch 91/100
100/100 [==============================] - 16s 161ms/step - loss: 0.3899 - acc: 0.8197 - val_loss: 0.4113 - val_acc: 0.8170
Epoch 92/100
100/100 [==============================] - 16s 158ms/step - loss: 0.3814 - acc: 0.8327 - val_loss: 0.3894 - val_acc: 0.8130
Epoch 93/100
100/100 [==============================] - 16s 160ms/step - loss: 0.3894 - acc: 0.8210 - val_loss: 0.4101 - val_acc: 0.8120
Epoch 94/100
100/100 [==============================] - 16s 160ms/step - loss: 0.3886 - acc: 0.8270 - val_loss: 0.4084 - val_acc: 0.8210
Epoch 95/100
100/100 [==============================] - 16s 159ms/step - loss: 0.3862 - acc: 0.8280 - val_loss: 0.4149 - val_acc: 0.8130
Epoch 96/100
100/100 [==============================] - 16s 159ms/step - loss: 0.3732 - acc: 0.8343 - val_loss: 0.3971 - val_acc: 0.8260
Epoch 97/100
100/100 [==============================] - 16s 161ms/step - loss: 0.3829 - acc: 0.8293 - val_loss: 0.4026 - val_acc: 0.8290
Epoch 98/100
100/100 [==============================] - 16s 162ms/step - loss: 0.3658 - acc: 0.8413 - val_loss: 0.4869 - val_acc: 0.7870
Epoch 99/100
100/100 [==============================] - 16s 160ms/step - loss: 0.3630 - acc: 0.8410 - val_loss: 0.4287 - val_acc: 0.8090
Epoch 100/100
100/100 [==============================] - 16s 157ms/step - loss: 0.3875 - acc: 0.8217 - val_loss: 0.4126 - val_acc: 0.8380
f, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 4))
t = f.suptitle('CNN with Image Augmentation Performance', fontsize=12)
f.subplots_adjust(top=0.85, wspace=0.3)
epoch_list = list(range(1,101))
ax1.plot(epoch_list, history.history['acc'], label='Train Accuracy')
ax1.plot(epoch_list, history.history['val_acc'], label='Validation Accuracy')
ax1.set_xticks(np.arange(0, 101, 10))
ax1.set_ylabel('Accuracy Value')
ax1.set_xlabel('Epoch')
ax1.set_title('Accuracy')
l1 = ax1.legend(loc="best")
ax2.plot(epoch_list, history.history['loss'], label='Train Loss')
ax2.plot(epoch_list, history.history['val_loss'], label='Validation Loss')
ax2.set_xticks(np.arange(0, 101, 10))
ax2.set_ylabel('Loss Value')
ax2.set_xlabel('Epoch')
ax2.set_title('Loss')
l2 = ax2.legend(loc="best")
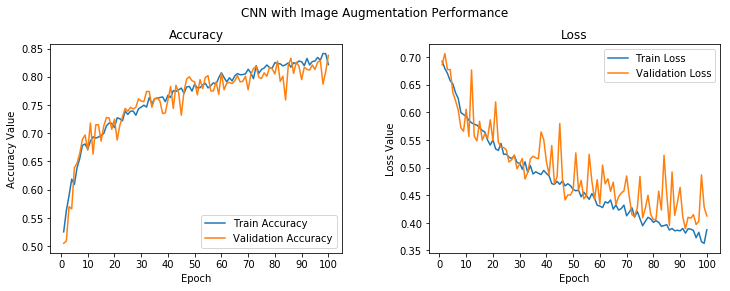
While there are some spikes in the validation accuracy and loss, overall, we see that it is much closer to the training accuracy, with the loss indicating that we obtained a model that generalizes much better as compared to our previous models.
model.save('cats_dogs_cnn_img_aug.h5')
In the hackathon we discussed the VGG-16 model in great length. An investigation into its properties can be found here with a notebook to follow. VGG stands for the Visual Geometry Group at the University of Oxford, which specializes in building very deep convolutional networks for large-scale visual recognition. The model looks like this:

You can clearly see that we have a total of 13 convolution layers using 3 x 3 convolution filters along with max pooling layers for downsampling and a total of two fully connected hidden layers of 4,096 units in each layer followed by a dense layer of 1,000 units, where each unit represents one of the image categories in the ImageNet database.
A pretrained model like the VGG-16 is an already trained model on a huge dataset (ImageNet) with a lot of diverse image categories. Considering this fact, the model should have learned a robust hierarchy of features, which are spatial, rotation, and translation invariant, as we have discussed before with regard to features learned by CNN models. Hence, the model, having learned a good representation of features for over a million images belonging to 1,000 different categories, can act as a good feature extractor for new images suitable for computer vision problems. These new images might never exist in the ImageNet dataset or might be of totally different categories, but the model should still be able to extract relevant features from these images.
from keras.applications import vgg16
from keras.models import Model
import keras
vgg = vgg16.VGG16(include_top=False, weights='imagenet',
input_shape=input_shape)
output = vgg.layers[-1].output
output = keras.layers.Flatten()(output)
vgg_model = Model(vgg.input, output)
vgg_model.trainable = False
for layer in vgg_model.layers:
layer.trainable = False
vgg_model.summary()
Downloading data from https://github.com/fchollet/deep-learning-models/releases/download/v0.1/vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5
58892288/58889256 [==============================] - 3s 0us/step
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 150, 150, 3) 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 150, 150, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 150, 150, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 75, 75, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 75, 75, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 75, 75, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 37, 37, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 37, 37, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 37, 37, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 37, 37, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 18, 18, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 18, 18, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 18, 18, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 18, 18, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 9, 9, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 9, 9, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 9, 9, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 9, 9, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 4, 4, 512) 0
_________________________________________________________________
flatten_4 (Flatten) (None, 8192) 0
=================================================================
Total params: 14,714,688
Trainable params: 0
Non-trainable params: 14,714,688
_________________________________________________________________
here all of the layers of the VGG-16 model are frozen because we don’t want their weights to change during model training. The last activation feature map in the VGG-16 model (output from block5_pool) gives us the bottleneck features, which can then be flattened and fed to a fully connected deep neural network classifier.
bottleneck_feature_example = vgg.predict(train_imgs_scaled[0:1])
print(bottleneck_feature_example.shape)
plt.imshow(bottleneck_feature_example[0][:,:,0])
(1, 4, 4, 512)
<matplotlib.image.AxesImage at 0x7fb5ed377278>
def get_bottleneck_features(model, input_imgs):
features = model.predict(input_imgs, verbose=0)
return features
train_features_vgg = get_bottleneck_features(vgg_model, train_imgs_scaled)
validation_features_vgg = get_bottleneck_features(vgg_model, validation_imgs_scaled)
print('Train Bottleneck Features:', train_features_vgg.shape,
'\tValidation Bottleneck Features:', validation_features_vgg.shape)
Train Bottleneck Features: (3000, 8192) Validation Bottleneck Features: (2850, 8192)
We flatten the bottleneck features in the vgg_model object to make them ready to be fed to our fully connected classifier. A way to save time in model training is to use this model and extract out all the features from our training and validation datasets and then feed them as inputs to our classifier. We extract the bottleneck features from our training and validation sets and build the model.
from keras.layers import InputLayer
input_shape = vgg_model.output_shape[1]
model = Sequential()
model.add(InputLayer(input_shape=(input_shape,)))
model.add(Dense(512, activation='relu', input_dim=input_shape))
model.add(Dropout(0.3))
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.3))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['accuracy'])
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) (None, 8192) 0
_________________________________________________________________
dense_9 (Dense) (None, 512) 4194816
_________________________________________________________________
dropout_5 (Dropout) (None, 512) 0
_________________________________________________________________
dense_10 (Dense) (None, 512) 262656
_________________________________________________________________
dropout_6 (Dropout) (None, 512) 0
_________________________________________________________________
dense_11 (Dense) (None, 1) 513
=================================================================
Total params: 4,457,985
Trainable params: 4,457,985
Non-trainable params: 0
_________________________________________________________________
history = model.fit(x=train_features_vgg, y=train_labels_enc,
validation_data=(validation_features_vgg, validation_labels_enc),
batch_size=batch_size,
epochs=epochs,
verbose=1)
Train on 3000 samples, validate on 2850 samples
Epoch 1/30
3000/3000 [==============================] - 1s 498us/step - loss: 0.4343 - acc: 0.7837 - val_loss: 0.3850 - val_acc: 0.8158
Epoch 2/30
3000/3000 [==============================] - 1s 385us/step - loss: 0.2918 - acc: 0.8750 - val_loss: 0.2931 - val_acc: 0.8726
Epoch 3/30
3000/3000 [==============================] - 1s 378us/step - loss: 0.2487 - acc: 0.8947 - val_loss: 0.2685 - val_acc: 0.8888
Epoch 4/30
3000/3000 [==============================] - 1s 374us/step - loss: 0.2075 - acc: 0.9140 - val_loss: 0.2718 - val_acc: 0.8881
Epoch 5/30
3000/3000 [==============================] - 1s 376us/step - loss: 0.1758 - acc: 0.9290 - val_loss: 0.2820 - val_acc: 0.8923
Epoch 6/30
3000/3000 [==============================] - 1s 361us/step - loss: 0.1556 - acc: 0.9380 - val_loss: 0.3473 - val_acc: 0.8712
Epoch 7/30
3000/3000 [==============================] - 1s 349us/step - loss: 0.1345 - acc: 0.9453 - val_loss: 0.3410 - val_acc: 0.8800
Epoch 8/30
3000/3000 [==============================] - 1s 348us/step - loss: 0.1133 - acc: 0.9553 - val_loss: 0.3431 - val_acc: 0.8839
Epoch 9/30
3000/3000 [==============================] - 1s 346us/step - loss: 0.0919 - acc: 0.9667 - val_loss: 0.3598 - val_acc: 0.8839
Epoch 10/30
3000/3000 [==============================] - 1s 337us/step - loss: 0.0754 - acc: 0.9717 - val_loss: 0.3763 - val_acc: 0.8839
Epoch 11/30
3000/3000 [==============================] - 1s 340us/step - loss: 0.0673 - acc: 0.9730 - val_loss: 0.4003 - val_acc: 0.8842
Epoch 12/30
3000/3000 [==============================] - 1s 346us/step - loss: 0.0406 - acc: 0.9873 - val_loss: 0.3774 - val_acc: 0.8881
Epoch 13/30
3000/3000 [==============================] - 1s 343us/step - loss: 0.0436 - acc: 0.9850 - val_loss: 0.4195 - val_acc: 0.8902
Epoch 14/30
3000/3000 [==============================] - 1s 340us/step - loss: 0.0386 - acc: 0.9860 - val_loss: 0.5522 - val_acc: 0.8758
Epoch 15/30
3000/3000 [==============================] - 1s 340us/step - loss: 0.0189 - acc: 0.9947 - val_loss: 0.5867 - val_acc: 0.8779
Epoch 16/30
3000/3000 [==============================] - 1s 335us/step - loss: 0.0245 - acc: 0.9920 - val_loss: 0.5097 - val_acc: 0.8888
Epoch 17/30
3000/3000 [==============================] - 1s 341us/step - loss: 0.0185 - acc: 0.9927 - val_loss: 0.5389 - val_acc: 0.8884
Epoch 18/30
3000/3000 [==============================] - 1s 344us/step - loss: 0.0157 - acc: 0.9937 - val_loss: 0.5486 - val_acc: 0.8912
Epoch 19/30
3000/3000 [==============================] - 1s 338us/step - loss: 0.0105 - acc: 0.9970 - val_loss: 0.5813 - val_acc: 0.8884
Epoch 20/30
3000/3000 [==============================] - 1s 335us/step - loss: 0.0064 - acc: 0.9987 - val_loss: 0.5884 - val_acc: 0.8895
Epoch 21/30
3000/3000 [==============================] - 1s 337us/step - loss: 0.0067 - acc: 0.9980 - val_loss: 0.7091 - val_acc: 0.8888
Epoch 22/30
3000/3000 [==============================] - 1s 335us/step - loss: 0.0057 - acc: 0.9987 - val_loss: 0.7213 - val_acc: 0.8867
Epoch 23/30
3000/3000 [==============================] - 1s 336us/step - loss: 0.0037 - acc: 0.9983 - val_loss: 0.7002 - val_acc: 0.8881
Epoch 24/30
3000/3000 [==============================] - 1s 337us/step - loss: 0.0154 - acc: 0.9940 - val_loss: 0.8044 - val_acc: 0.8775
Epoch 25/30
3000/3000 [==============================] - 1s 339us/step - loss: 0.0072 - acc: 0.9980 - val_loss: 0.7229 - val_acc: 0.8902
Epoch 26/30
3000/3000 [==============================] - 1s 338us/step - loss: 0.0090 - acc: 0.9973 - val_loss: 0.7200 - val_acc: 0.8895
Epoch 27/30
3000/3000 [==============================] - 1s 338us/step - loss: 0.0044 - acc: 0.9987 - val_loss: 1.1443 - val_acc: 0.8411
Epoch 28/30
3000/3000 [==============================] - 1s 337us/step - loss: 0.0090 - acc: 0.9980 - val_loss: 0.7532 - val_acc: 0.8860
Epoch 29/30
3000/3000 [==============================] - 1s 337us/step - loss: 0.0021 - acc: 0.9997 - val_loss: 0.8280 - val_acc: 0.8881
Epoch 30/30
3000/3000 [==============================] - 1s 335us/step - loss: 0.0043 - acc: 0.9990 - val_loss: 0.8282 - val_acc: 0.8860
f, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 4))
t = f.suptitle('Pre-trained CNN (Transfer Learning) Performance', fontsize=12)
f.subplots_adjust(top=0.85, wspace=0.3)
epoch_list = list(range(1,31))
ax1.plot(epoch_list, history.history['acc'], label='Train Accuracy')
ax1.plot(epoch_list, history.history['val_acc'], label='Validation Accuracy')
ax1.set_xticks(np.arange(0, 31, 5))
ax1.set_ylabel('Accuracy Value')
ax1.set_xlabel('Epoch')
ax1.set_title('Accuracy')
l1 = ax1.legend(loc="best")
ax2.plot(epoch_list, history.history['loss'], label='Train Loss')
ax2.plot(epoch_list, history.history['val_loss'], label='Validation Loss')
ax2.set_xticks(np.arange(0, 31, 5))
ax2.set_ylabel('Loss Value')
ax2.set_xlabel('Epoch')
ax2.set_title('Loss')
l2 = ax2.legend(loc="best")
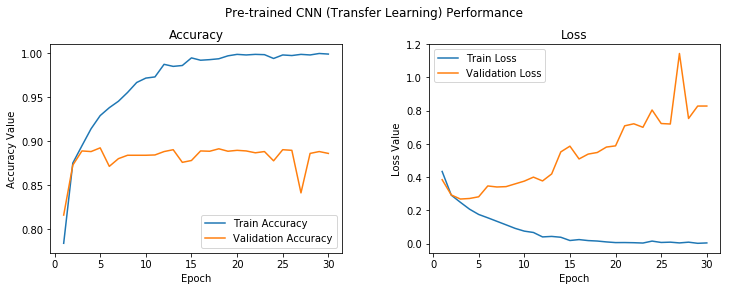
model.save('cats_dogs_tlearn_basic_cnn.h5')
Even though this model is overfitting on the training data after only about 5 epochs overall, this seems to be the best model so far, with close to 90% validation accuracy without even using an image augmentation strategy so let’s do that now.
train_datagen = ImageDataGenerator(rescale=1./255, zoom_range=0.3, rotation_range=50,
width_shift_range=0.2, height_shift_range=0.2, shear_range=0.2,
horizontal_flip=True, fill_mode='nearest')
val_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow(train_imgs, train_labels_enc, batch_size=30)
val_generator = val_datagen.flow(validation_imgs, validation_labels_enc, batch_size=20)
model = Sequential()
model.add(vgg_model)
model.add(Dense(512, activation='relu', input_dim=input_shape))
model.add(Dropout(0.3))
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.3))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=2e-5),
metrics=['accuracy'])
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
model_1 (Model) (None, 8192) 14714688
_________________________________________________________________
dense_12 (Dense) (None, 512) 4194816
_________________________________________________________________
dropout_7 (Dropout) (None, 512) 0
_________________________________________________________________
dense_13 (Dense) (None, 512) 262656
_________________________________________________________________
dropout_8 (Dropout) (None, 512) 0
_________________________________________________________________
dense_14 (Dense) (None, 1) 513
=================================================================
Total params: 19,172,673
Trainable params: 4,457,985
Non-trainable params: 14,714,688
_________________________________________________________________
history = model.fit_generator(train_generator, steps_per_epoch=100, epochs=100,
validation_data=val_generator, validation_steps=50, verbose=1)
Epoch 1/100
100/100 [==============================] - 40s 403ms/step - loss: 0.6549 - acc: 0.6043 - val_loss: 0.5037 - val_acc: 0.8040
Epoch 2/100
100/100 [==============================] - 37s 368ms/step - loss: 0.5672 - acc: 0.7110 - val_loss: 0.4164 - val_acc: 0.8410
Epoch 3/100
100/100 [==============================] - 37s 368ms/step - loss: 0.5060 - acc: 0.7487 - val_loss: 0.3714 - val_acc: 0.8460
Epoch 4/100
100/100 [==============================] - 37s 368ms/step - loss: 0.4694 - acc: 0.7757 - val_loss: 0.3469 - val_acc: 0.8520
Epoch 5/100
100/100 [==============================] - 37s 368ms/step - loss: 0.4577 - acc: 0.7800 - val_loss: 0.3271 - val_acc: 0.8650
Epoch 6/100
100/100 [==============================] - 37s 368ms/step - loss: 0.4437 - acc: 0.7940 - val_loss: 0.3479 - val_acc: 0.8570
Epoch 7/100
100/100 [==============================] - 37s 368ms/step - loss: 0.4248 - acc: 0.8007 - val_loss: 0.3315 - val_acc: 0.8600
Epoch 8/100
100/100 [==============================] - 37s 368ms/step - loss: 0.4085 - acc: 0.8173 - val_loss: 0.3115 - val_acc: 0.8600
Epoch 9/100
100/100 [==============================] - 37s 368ms/step - loss: 0.3985 - acc: 0.8070 - val_loss: 0.2987 - val_acc: 0.8690
Epoch 10/100
100/100 [==============================] - 37s 368ms/step - loss: 0.3872 - acc: 0.8270 - val_loss: 0.3129 - val_acc: 0.8640
Epoch 11/100
100/100 [==============================] - 37s 369ms/step - loss: 0.3780 - acc: 0.8347 - val_loss: 0.2854 - val_acc: 0.8830
Epoch 12/100
100/100 [==============================] - 37s 368ms/step - loss: 0.3757 - acc: 0.8280 - val_loss: 0.2944 - val_acc: 0.8680
Epoch 13/100
100/100 [==============================] - 37s 368ms/step - loss: 0.3831 - acc: 0.8290 - val_loss: 0.2826 - val_acc: 0.8780
Epoch 14/100
100/100 [==============================] - 37s 368ms/step - loss: 0.3777 - acc: 0.8353 - val_loss: 0.3072 - val_acc: 0.8690
Epoch 15/100
100/100 [==============================] - 37s 368ms/step - loss: 0.3683 - acc: 0.8293 - val_loss: 0.3095 - val_acc: 0.8590
Epoch 16/100
100/100 [==============================] - 37s 368ms/step - loss: 0.3815 - acc: 0.8333 - val_loss: 0.2778 - val_acc: 0.8790
Epoch 17/100
100/100 [==============================] - 37s 368ms/step - loss: 0.3599 - acc: 0.8357 - val_loss: 0.2717 - val_acc: 0.8900
Epoch 18/100
100/100 [==============================] - 37s 368ms/step - loss: 0.3618 - acc: 0.8327 - val_loss: 0.2887 - val_acc: 0.8730
Epoch 19/100
100/100 [==============================] - 37s 368ms/step - loss: 0.3664 - acc: 0.8387 - val_loss: 0.2729 - val_acc: 0.8790
Epoch 20/100
100/100 [==============================] - 37s 368ms/step - loss: 0.3514 - acc: 0.8423 - val_loss: 0.2734 - val_acc: 0.8800
Epoch 21/100
100/100 [==============================] - 37s 368ms/step - loss: 0.3586 - acc: 0.8323 - val_loss: 0.2646 - val_acc: 0.8850
Epoch 22/100
100/100 [==============================] - 37s 368ms/step - loss: 0.3501 - acc: 0.8470 - val_loss: 0.2774 - val_acc: 0.8780
Epoch 23/100
100/100 [==============================] - 37s 368ms/step - loss: 0.3431 - acc: 0.8447 - val_loss: 0.2647 - val_acc: 0.8870
Epoch 24/100
100/100 [==============================] - 37s 368ms/step - loss: 0.3317 - acc: 0.8457 - val_loss: 0.2706 - val_acc: 0.8800
Epoch 25/100
100/100 [==============================] - 37s 368ms/step - loss: 0.3489 - acc: 0.8490 - val_loss: 0.2658 - val_acc: 0.8830
Epoch 26/100
100/100 [==============================] - 37s 368ms/step - loss: 0.3431 - acc: 0.8470 - val_loss: 0.2858 - val_acc: 0.8720
Epoch 27/100
100/100 [==============================] - 37s 368ms/step - loss: 0.3282 - acc: 0.8587 - val_loss: 0.2748 - val_acc: 0.8820
Epoch 28/100
100/100 [==============================] - 37s 368ms/step - loss: 0.3310 - acc: 0.8567 - val_loss: 0.2755 - val_acc: 0.8750
Epoch 29/100
100/100 [==============================] - 37s 368ms/step - loss: 0.3342 - acc: 0.8490 - val_loss: 0.2687 - val_acc: 0.8810
Epoch 30/100
100/100 [==============================] - 37s 368ms/step - loss: 0.3419 - acc: 0.8433 - val_loss: 0.2794 - val_acc: 0.8770
Epoch 31/100
100/100 [==============================] - 37s 368ms/step - loss: 0.3310 - acc: 0.8573 - val_loss: 0.2560 - val_acc: 0.8940
Epoch 32/100
100/100 [==============================] - 37s 368ms/step - loss: 0.3227 - acc: 0.8567 - val_loss: 0.2563 - val_acc: 0.8930
Epoch 33/100
100/100 [==============================] - 37s 368ms/step - loss: 0.3349 - acc: 0.8543 - val_loss: 0.2622 - val_acc: 0.8870
Epoch 34/100
100/100 [==============================] - 37s 368ms/step - loss: 0.3255 - acc: 0.8517 - val_loss: 0.2571 - val_acc: 0.8910
Epoch 35/100
100/100 [==============================] - 37s 368ms/step - loss: 0.3278 - acc: 0.8567 - val_loss: 0.2807 - val_acc: 0.8800
Epoch 36/100
100/100 [==============================] - 37s 368ms/step - loss: 0.3248 - acc: 0.8570 - val_loss: 0.2637 - val_acc: 0.8870
Epoch 37/100
100/100 [==============================] - 37s 369ms/step - loss: 0.3242 - acc: 0.8510 - val_loss: 0.2633 - val_acc: 0.8890
Epoch 38/100
100/100 [==============================] - 37s 368ms/step - loss: 0.3300 - acc: 0.8573 - val_loss: 0.2663 - val_acc: 0.8840
Epoch 39/100
100/100 [==============================] - 37s 368ms/step - loss: 0.3391 - acc: 0.8460 - val_loss: 0.2618 - val_acc: 0.8870
Epoch 40/100
100/100 [==============================] - 37s 368ms/step - loss: 0.3152 - acc: 0.8577 - val_loss: 0.2545 - val_acc: 0.8920
Epoch 41/100
100/100 [==============================] - 37s 368ms/step - loss: 0.3141 - acc: 0.8570 - val_loss: 0.2514 - val_acc: 0.8980
Epoch 42/100
100/100 [==============================] - 37s 368ms/step - loss: 0.3280 - acc: 0.8563 - val_loss: 0.2614 - val_acc: 0.8900
Epoch 43/100
100/100 [==============================] - 37s 368ms/step - loss: 0.3151 - acc: 0.8563 - val_loss: 0.2704 - val_acc: 0.8820
Epoch 44/100
100/100 [==============================] - 37s 368ms/step - loss: 0.3247 - acc: 0.8490 - val_loss: 0.2700 - val_acc: 0.8860
Epoch 45/100
100/100 [==============================] - 37s 368ms/step - loss: 0.3109 - acc: 0.8597 - val_loss: 0.2688 - val_acc: 0.8890
Epoch 46/100
100/100 [==============================] - 37s 368ms/step - loss: 0.3122 - acc: 0.8617 - val_loss: 0.2623 - val_acc: 0.8880
Epoch 47/100
100/100 [==============================] - 37s 368ms/step - loss: 0.3158 - acc: 0.8567 - val_loss: 0.2646 - val_acc: 0.8900
Epoch 48/100
100/100 [==============================] - 37s 368ms/step - loss: 0.3242 - acc: 0.8550 - val_loss: 0.2570 - val_acc: 0.8950
Epoch 49/100
100/100 [==============================] - 37s 368ms/step - loss: 0.3139 - acc: 0.8680 - val_loss: 0.2569 - val_acc: 0.8930
Epoch 50/100
100/100 [==============================] - 37s 368ms/step - loss: 0.3102 - acc: 0.8673 - val_loss: 0.2606 - val_acc: 0.8890
Epoch 51/100
100/100 [==============================] - 37s 368ms/step - loss: 0.3244 - acc: 0.8553 - val_loss: 0.2630 - val_acc: 0.8880
Epoch 52/100
100/100 [==============================] - 37s 368ms/step - loss: 0.3072 - acc: 0.8687 - val_loss: 0.2508 - val_acc: 0.8990
Epoch 53/100
100/100 [==============================] - 37s 368ms/step - loss: 0.3115 - acc: 0.8647 - val_loss: 0.2577 - val_acc: 0.8930
Epoch 54/100
100/100 [==============================] - 37s 368ms/step - loss: 0.2972 - acc: 0.8817 - val_loss: 0.2733 - val_acc: 0.8820
Epoch 55/100
100/100 [==============================] - 37s 368ms/step - loss: 0.2971 - acc: 0.8650 - val_loss: 0.2748 - val_acc: 0.8850
Epoch 56/100
100/100 [==============================] - 37s 368ms/step - loss: 0.2947 - acc: 0.8723 - val_loss: 0.2505 - val_acc: 0.8960
Epoch 57/100
100/100 [==============================] - 37s 368ms/step - loss: 0.2982 - acc: 0.8663 - val_loss: 0.2469 - val_acc: 0.8970
Epoch 58/100
100/100 [==============================] - 37s 368ms/step - loss: 0.2963 - acc: 0.8703 - val_loss: 0.2482 - val_acc: 0.8990
Epoch 59/100
100/100 [==============================] - 37s 368ms/step - loss: 0.3031 - acc: 0.8693 - val_loss: 0.2506 - val_acc: 0.8940
Epoch 60/100
100/100 [==============================] - 37s 368ms/step - loss: 0.3020 - acc: 0.8643 - val_loss: 0.2450 - val_acc: 0.8950
Epoch 61/100
100/100 [==============================] - 37s 368ms/step - loss: 0.3147 - acc: 0.8670 - val_loss: 0.2451 - val_acc: 0.8930
Epoch 62/100
100/100 [==============================] - 37s 368ms/step - loss: 0.3019 - acc: 0.8733 - val_loss: 0.2525 - val_acc: 0.8920
Epoch 63/100
100/100 [==============================] - 37s 368ms/step - loss: 0.2974 - acc: 0.8677 - val_loss: 0.2429 - val_acc: 0.9010
Epoch 64/100
100/100 [==============================] - 37s 369ms/step - loss: 0.3001 - acc: 0.8693 - val_loss: 0.2557 - val_acc: 0.8940
Epoch 65/100
100/100 [==============================] - 37s 368ms/step - loss: 0.2980 - acc: 0.8690 - val_loss: 0.2619 - val_acc: 0.8870
Epoch 66/100
100/100 [==============================] - 37s 368ms/step - loss: 0.2882 - acc: 0.8753 - val_loss: 0.2666 - val_acc: 0.8860
Epoch 67/100
100/100 [==============================] - 37s 368ms/step - loss: 0.2952 - acc: 0.8730 - val_loss: 0.2557 - val_acc: 0.8920
Epoch 68/100
100/100 [==============================] - 37s 368ms/step - loss: 0.3040 - acc: 0.8657 - val_loss: 0.2400 - val_acc: 0.8970
Epoch 69/100
100/100 [==============================] - 37s 368ms/step - loss: 0.2939 - acc: 0.8750 - val_loss: 0.2502 - val_acc: 0.8980
Epoch 70/100
100/100 [==============================] - 37s 368ms/step - loss: 0.2983 - acc: 0.8670 - val_loss: 0.2712 - val_acc: 0.8820
Epoch 71/100
100/100 [==============================] - 37s 368ms/step - loss: 0.2864 - acc: 0.8750 - val_loss: 0.2547 - val_acc: 0.8930
Epoch 72/100
100/100 [==============================] - 37s 368ms/step - loss: 0.2821 - acc: 0.8763 - val_loss: 0.2436 - val_acc: 0.8910
Epoch 73/100
100/100 [==============================] - 37s 368ms/step - loss: 0.2871 - acc: 0.8767 - val_loss: 0.2569 - val_acc: 0.8920
Epoch 74/100
100/100 [==============================] - 37s 368ms/step - loss: 0.2933 - acc: 0.8763 - val_loss: 0.2526 - val_acc: 0.8940
Epoch 75/100
100/100 [==============================] - 37s 368ms/step - loss: 0.2901 - acc: 0.8737 - val_loss: 0.2495 - val_acc: 0.8980
Epoch 76/100
100/100 [==============================] - 37s 368ms/step - loss: 0.2887 - acc: 0.8750 - val_loss: 0.2406 - val_acc: 0.8990
Epoch 77/100
100/100 [==============================] - 37s 368ms/step - loss: 0.2857 - acc: 0.8743 - val_loss: 0.2725 - val_acc: 0.8850
Epoch 78/100
100/100 [==============================] - 37s 368ms/step - loss: 0.2903 - acc: 0.8743 - val_loss: 0.2448 - val_acc: 0.9020
Epoch 79/100
100/100 [==============================] - 37s 369ms/step - loss: 0.2982 - acc: 0.8687 - val_loss: 0.2385 - val_acc: 0.8990
Epoch 80/100
100/100 [==============================] - 37s 368ms/step - loss: 0.2909 - acc: 0.8727 - val_loss: 0.2484 - val_acc: 0.8880
Epoch 81/100
100/100 [==============================] - 37s 368ms/step - loss: 0.2790 - acc: 0.8853 - val_loss: 0.2634 - val_acc: 0.8910
Epoch 82/100
100/100 [==============================] - 37s 368ms/step - loss: 0.3031 - acc: 0.8703 - val_loss: 0.2397 - val_acc: 0.8990
Epoch 83/100
100/100 [==============================] - 37s 368ms/step - loss: 0.2866 - acc: 0.8853 - val_loss: 0.2530 - val_acc: 0.9000
Epoch 84/100
100/100 [==============================] - 37s 368ms/step - loss: 0.2755 - acc: 0.8833 - val_loss: 0.2655 - val_acc: 0.8890
Epoch 85/100
100/100 [==============================] - 37s 368ms/step - loss: 0.2852 - acc: 0.8783 - val_loss: 0.2547 - val_acc: 0.8980
Epoch 86/100
100/100 [==============================] - 37s 368ms/step - loss: 0.2750 - acc: 0.8840 - val_loss: 0.2547 - val_acc: 0.8980
Epoch 87/100
100/100 [==============================] - 37s 368ms/step - loss: 0.2908 - acc: 0.8737 - val_loss: 0.2429 - val_acc: 0.8950
Epoch 88/100
100/100 [==============================] - 37s 368ms/step - loss: 0.2784 - acc: 0.8820 - val_loss: 0.2489 - val_acc: 0.9040
Epoch 89/100
100/100 [==============================] - 37s 368ms/step - loss: 0.2889 - acc: 0.8763 - val_loss: 0.2506 - val_acc: 0.8990
Epoch 90/100
100/100 [==============================] - 37s 368ms/step - loss: 0.2775 - acc: 0.8807 - val_loss: 0.2418 - val_acc: 0.8970
Epoch 91/100
100/100 [==============================] - 37s 368ms/step - loss: 0.2775 - acc: 0.8870 - val_loss: 0.2581 - val_acc: 0.8990
Epoch 92/100
100/100 [==============================] - 37s 368ms/step - loss: 0.2771 - acc: 0.8813 - val_loss: 0.2430 - val_acc: 0.8920
Epoch 93/100
100/100 [==============================] - 37s 368ms/step - loss: 0.2791 - acc: 0.8793 - val_loss: 0.2457 - val_acc: 0.9010
Epoch 94/100
100/100 [==============================] - 37s 368ms/step - loss: 0.2944 - acc: 0.8787 - val_loss: 0.2407 - val_acc: 0.8950
Epoch 95/100
100/100 [==============================] - 37s 368ms/step - loss: 0.2830 - acc: 0.8820 - val_loss: 0.2465 - val_acc: 0.9020
Epoch 96/100
100/100 [==============================] - 37s 368ms/step - loss: 0.2825 - acc: 0.8767 - val_loss: 0.2491 - val_acc: 0.9030
Epoch 97/100
100/100 [==============================] - 37s 368ms/step - loss: 0.2890 - acc: 0.8760 - val_loss: 0.2489 - val_acc: 0.9000
Epoch 98/100
100/100 [==============================] - 37s 368ms/step - loss: 0.2757 - acc: 0.8830 - val_loss: 0.2626 - val_acc: 0.8970
Epoch 99/100
100/100 [==============================] - 37s 368ms/step - loss: 0.2821 - acc: 0.8843 - val_loss: 0.2438 - val_acc: 0.9040
Epoch 100/100
100/100 [==============================] - 37s 368ms/step - loss: 0.2819 - acc: 0.8773 - val_loss: 0.2466 - val_acc: 0.9030
f, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 4))
t = f.suptitle('Pre-trained CNN (Transfer Learning) with Image Augmentation Performance', fontsize=12)
f.subplots_adjust(top=0.85, wspace=0.3)
epoch_list = list(range(1,101))
ax1.plot(epoch_list, history.history['acc'], label='Train Accuracy')
ax1.plot(epoch_list, history.history['val_acc'], label='Validation Accuracy')
ax1.set_xticks(np.arange(0, 101, 10))
ax1.set_ylabel('Accuracy Value')
ax1.set_xlabel('Epoch')
ax1.set_title('Accuracy')
l1 = ax1.legend(loc="best")
ax2.plot(epoch_list, history.history['loss'], label='Train Loss')
ax2.plot(epoch_list, history.history['val_loss'], label='Validation Loss')
ax2.set_xticks(np.arange(0, 101, 10))
ax2.set_ylabel('Loss Value')
ax2.set_xlabel('Epoch')
ax2.set_title('Loss')
l2 = ax2.legend(loc="best")
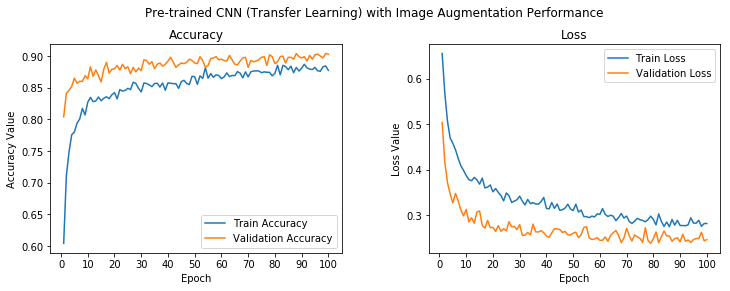
We can see that our model has an overall validation accuracy of 85%, which is a slight improvement from our previous model, and also the train and validation accuracy are quite close to each other, indicating that the model is not overfitting.
model.save('cats_dogs_tlearn_img_aug_cnn.h5')
